
AVX2 Support in Visual Studio C++ Compiler
AVX2 is yet another extension to the venerable x86 line of processors, doubling the width of its SIMD vector registers to 256 bits, and adding dozens of new instructions. AVX2 shipped with Intel’s latest processor micro-architecture, codenamed “Haswell“. (Its official name is “4th generation Intel® Core™ processor family”). As well as AVX2, Haswell supports other features to help make your code run faster: FMA (Fused Multiply Add) and BMI (Bit Manipulation Instructions), in particular. Haswell chips appear in many of the latest PCs, laptops and tablets (including our own Surface Pro 2).
This extra silicon opens a new corner of the playing field for compiler-writers – to take your C++ source and generate these new instructions, making your code run faster than before. And so we are releasing our initial support for AVX2 with the CTP2 of Visual Studio Update.
How do you tell the VC++ compiler to generate AVX2 instruction? From the command line, include the /arch:AVX2 switch. If you work within Visual Studio, the screenshot below shows how to set this option.
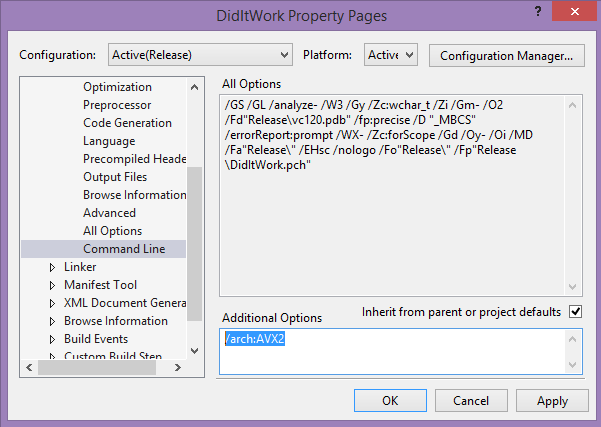
Yes, we will add an option to enable AVX2 in the drop-down menu at: Project Property Pages | Configuration Properties | C/C++ | Code Generation | Enable Enhanced Instruction Set. Likewise, we will add brief help to the command line usage for cl /?
Further points worth calling out on AVX2 support:
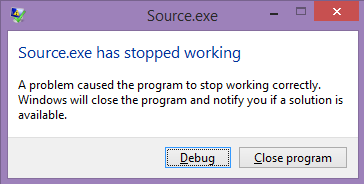
The compiler will generate code that includes AVX2 and FMA instructions. The resulting binaries will only run on PCs that support these instructions. If you run the binaries on an older PC, the program will crash, and display a popup like this:
If you specify /arch:AVX2, then it also enables /arch:AVX – we try to keep those /arch switches ‘monotonic’: the capabilities of each switch in the sequence {IA32, SSE, SSE2, AVX, AVX2} subsumes its predecessor (not sure I’ve explained this well – is it clear?)
The AVX2 support in this CTP is just a start. We have more work to do! This really should not come as a surprise – in a sense, compiler optimizations are never “finished”. Compiler engineers have been improving optimizations since they were started in the mid-50s by John Backus in the FORTRAN I project. But it’s worth emphasizing, if only to fend off a little flurry of advice saying we could improve parts of our AVX2 codegen 🙂
If you want to write code that checks for whether the machine you are running is “Haswell-capable”, then you need to check 5 configuration bits, via the CPUID instruction. This Intel page explains the details.
As always, we are interested in your feedback. Post your comments below. Thanks!
 Light
Light Dark
Dark
0 comments